
ML ベースのコンピューター ビジョン アプローチの出現により、人々はビデオ データの価値を簡単に活用できるようになりました。ビデオクリップの分析に多くの時間と労力を費やすことなく、必要なものを取得できます。次に、ビデオ認識の世界に入り、それが何であり、どのように機能するかを理解しましょう。この記事では、6 つの強力なビデオ認識ソフトウェアも集めました。それらを使用して、目的のデータ情報を取得できます。
ビデオ認識とは?
ビデオ認識は、視覚的なソース (ビデオ) からデータを取得、処理、および分析する機械の機能です。簡単に言えば、マシンがビデオを「見て」、フレームごとに受け取った情報を「理解」できるようにします。対象の物体や車両などの挙動に関するビデオ データを分析できます。

画像認識とビデオ認識の最も明白な違いは、ビデオ トラッキングです。 ML ベースのコンピューター ビジョン アプローチでは、カメラを使用して、時間の経過とともに移動するオブジェクトを特定します。主に、この移動するターゲット オブジェクトを連続したビデオ フレームに関連付けます。
この識別技術はコンピューター ビジョンのようなもので、ディープ ラーニングに依存しています。機械学習のアイデアは、何らかの入力を出力にマッピングすることによって人々に表現されます。具体的には、入力を提案すると、アルゴリズムが出力に対する答えを教えてくれます。その中で、人工ニューラル ネットワークは私たちの疑問に対する答えを提供してくれます。
がある 優れた知性を持つ人工知能 ビデオ認識で。社会では、ビデオはセキュリティ調査や法執行状況における重要な証拠です。これらのビデオには多くの貴重なデータがあります。 AI映像認識調査で、映像から欲しい情報を簡単に取得できます。
多くの場合、ビデオ コンテンツ分析またはインテリジェント ビデオ分析と呼ばれます。これは、ビデオ認識に関連する多くの異なるタスクがあるためです。人には理由もある 人工知能を使う ビデオ認識用。調査時間を大幅に短縮できます。調査にかかる時間は、数週間または数か月からわずか数秒に短縮されます。また、これらの大量のビデオ データを処理するのにも役立ち、物事をより早く終わらせることができます。
ビデオ認識の歴史
ビデオ認識は、コンピューターが画像を解釈して理解できるようにするために 1960 年代に登場したコンピューター ビジョンにルーツがあります。長年にわたり、人工知能と機械学習の進歩により、より洗練されたビデオ認識アルゴリズムが開発されてきました。 2000 年代初頭、ビデオ映像をリアルタイムで分析して疑わしいアクティビティを特定できる監視システムの開発により、ML ベースのコンピューター ビジョン アプローチがセキュリティ業界で勢いを増し始めました。
ビデオ認識はどのように機能しますか?
ビデオ認識は拡張を組み合わせます ディープラーニング (DL) と コンピュータビジョン (CV) モデル。次に、AI を使用して、ライブ ビデオ ストリームと録画されたビデオ クリップの両方を適用し、タスクを完了します。 AI ビデオ認識が機能する最も一般的な方法は次のとおりです。

- 画像分類: これを使用して、ビデオに適したカテゴリを選択できます。
- 物体検出: ビデオ内のオブジェクトをすばやく分類して見つけるのに役立ちます。
- ポジショニング: これを使用して、ビデオ内のターゲット オブジェクトを見つけることができます。
- オブジェクトの識別: ターゲット オブジェクト インスタンス
- オブジェクト追跡: ターゲット オブジェクトのモーション トラジェクトリを追跡できます。ターゲット オブジェクトのモーション軌跡は、ビデオで異なります。
ビデオ認識と顔認識の違いは何ですか?
ML ベースのコンピューター ビジョン アプローチは、多くのビデオ ソースからの受信データをフレームごとに認識することに重点を置いています。人工知能を使用して、このビデオ データをすばやく処理します。結果を得るために必要な時間はわずかです。

顔認識一方、 は、顔が存在することを認識する (顔検出) 生体認証技術です。顔認識により、顔の所有者をすばやく特定します。顔認識も人工知能を使用しています。ここでは、人工知能がコンピュータ アプリケーションを使用して動作します。このアプリケーションは、個人の顔のデジタル画像をすばやくキャプチャするのに役立ちます。アプリケーションは、ビデオ フレームからそのターゲット オブジェクトのデジタル画像を取得します。次に、このデジタル画像をデータベース レコードに保存されている画像と比較します。探したい対象物を簡単に見つけることができます。
ビデオ内のオブジェクトを識別するにはどうすればよいですか?
ML ベースのコンピューター ビジョン アプローチは、コンピューター ビジョンを使用してビデオ内のオブジェクトを識別し、それらに関する情報を返すテクノロジです。
ビデオ認識の最初のステップは、ビデオ データを収集することです。これは、人々にビデオに注釈を付けてもらうか、1 秒あたり 1 フレームでシーンをキャプチャするカメラから収集することで実行できます。
動画データを取得したら、分析を開始できます。これにはいくつかの方法があります。
- オブジェクト検出アルゴリズムを使用して、画像内のオブジェクト (顔、車など) を検出します。
- セマンティック セグメンテーション手法 (辞書などを使用) を使用して、イメージを個々のオブジェクトにセグメント化します。
- データ セット内のパターンを探します (たとえば、データセット内に車の画像よりも顔の画像が多い場合、アルゴリズムは顔の識別に重点を置く必要があります)。各オブジェクト タイプの特定の例 (車と顔など) を探すだけではありません。
私たちの生活の中で一般的なビデオ認識アプリケーションにはどのようなものがありますか?
ビデオ認識システムは、さまざまな業界やビジネス プロセスに存在します。私たちの生活でもよく見かけます。以下は、より一般的なビデオ認識アプリケーションの一部です。
人間活動認識
一定の順序でオペレータが実行するタスクに適用されます。これは主に、商業、産業、および医療のシナリオで発生します。
- 工業生産: 自動化された組立ライン生産と完成品の QC
- 小売り: ラベル付き商品の販売や棚卸し、生鮮食品の取り扱いがある方
- ロジスティクスと倉庫: 倉庫での商品のパレットの取り扱い。一部の壊れやすい/貴重品の取り扱いには、輸送時に注意が必要です。
- 健康管理: 病院は、患者ケアプロバイダーのテストにそれらを使用します。これらの重大な外傷の場合に特に適しています。
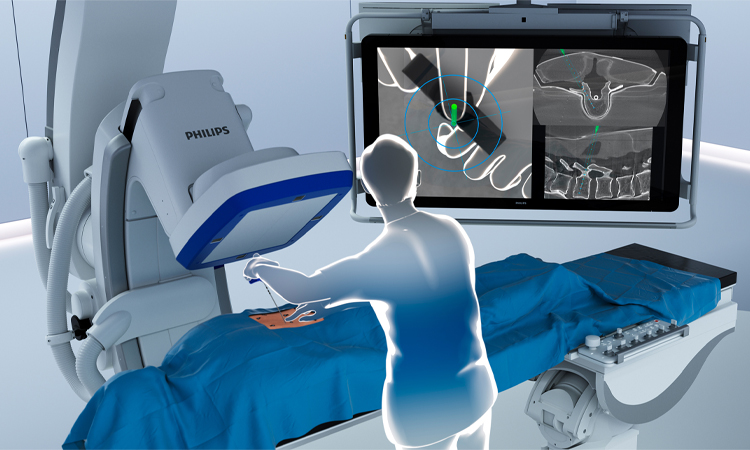
外科用機器の監視と制御
ほとんどの外科用機器は、医療スタッフによる正確な動きの制御を必要とします。医師が密集した血管や臓器を肉眼で特定すると、医療ミスが発生しやすくなります。この閉ループ プロセスには、ビデオ認識のための強力な認識および処理テクノロジが必要です。
- 手術器具の寿命の監視: 手術室では、医療スタッフがツールの残りの寿命を見積もることができます。これにより、医療スタッフは、ツールが寿命の途中で寿命を迎えないようにすることができます。
- 医療ツールの使用におけるベスト プラクティスの確保: 医師が多くの診断ツールを持っている場合に、医師が規則に従うことを保証します。この規則は、安全に使用するために推奨される順序を具体的に示しています。
- 次善のアクションを取得します。 ビデオは、他の利用可能なセンサー フィードバックと共に使用されます。外科的活動の評価の進行状態の変化を得ることができます。成功スコアの確率が高いアクションの推奨事項を取得できます。
6つの最高のビデオ認識ソフトウェア
Video Recognition Software (VRS) は、AI 駆動型のソフトウェアです。デジタル ビデオ監視システムと組み合わせて使用できます。両方を組み合わせると、脅威の存在を特定して検出するのに役立ちます。これらの脅威の存在は、ナイフや銃器などの比較的単一のオブジェクトである可能性があります。また、比較的複雑な障害や群衆の動きである場合もあります。 VRS はセキュリティ担当者の目を集中させ、脅威をより迅速に検出できるようにします。次に、優れたビデオ認識ソフトウェアを6つ紹介します。

新星AI
Nova AI は、主にさまざまな音声および認識技術を採用することで、ユーザーを支援します。このソフトウェアを使用すると、コンテンツの細部を分類および処理できます。コンピューター ビジョン テクノロジーを使用して、人生の重要な瞬間をすべて抽出して発見します。このソフトウェアを使用すると、クラウド アカウントを介して、検出された最新のメタデータを保存できます。また、ビデオ内で人間の音声と使用可能な音声を区別するためにも使用できます。 Nova AI は、ビデオ データを操作する際の大きな助けになると確信しています。
センシファイ
Sensifai は AI ツールを使用して、リアルタイムで再生される画像や動画を認識します。象徴的なアクション、シーン、オブジェクト、有名人を識別するように設計されています。このソフトウェアは、ビデオや画像内の未開の暴力や冒とく的な表現を見つけてフラグを立てるのに役立ちます。これを使用して、画像やビデオで何千ものアクション、オブジェクト、動きをマークできます。また、爆発、火災、不審な音の識別にも使用できます。また、これらのオーディオおよびビデオ ファイルに字幕を自動的に追加します。これを使用すると、必要なオーディオ ファイルとビデオ ファイルを簡単に検索できます。特に、愛する人を一人で追跡するためにも使用できます。あなたの愛する人が脅威を感じたときに警告します。 Sensifai は、さまざまなシナリオに適しています。
物体検出
このソフトウェアは、コンピュータを強力なビデオ セキュリティ システムに変えることができます。会社や自宅で発生するすべてをリモートで追跡できます。人工知能を使用して、ターゲット オブジェクトをリアルタイムで追跡および識別します。よりリッチなビデオ監視コンテンツを取得できます。このソフトウェアには、ウェブカメラ クラウドもあります。それを介して、人工知能ベースのビデオ監視を使用できます。 Object Detection は、ビデオ監視クラウドに非常に適したソフトウェアです。ソフトウェアは、保存されたビデオを特定の時間に指定されたチャネルまたはメディア ソフトウェアに自動的にアップロードします。
クラウド ビデオ インテリジェンス API
Cloud Video Intelligence API は、主に Google Cloud を利用しています。多くの強力なコンテンツの発見を可能にし、人々に魅力的なビデオ体験をもたらします。このソフトウェアには、正確なビデオ分析機能があります。ビデオ内の 20,000 を超える場所、位置、アクション、オブジェクトを識別できます。これは、新しいメディア オペレーターがビデオ フレーム レベルまたはフッテージからリッチ メタデータを抽出するのに役立ちます。 AutoML Video Intelligence を使用して、エンティティ タグの作成を支援することもできます。ソフトウェアのオブジェクトベースのイベント トリガーとストリーミング ビデオ注釈を使用して、より正確な洞察を得ることができます。また、お客様の声やハイライト クリップを使用して、優れたカスタマー エクスペリエンスを構築するのにも役立ちます。
ヴァロッサ
Valossa を使用すると、オーディオおよびビデオ データのコンテンツの真の意味を明らかにすることができます。このコグニティブ AI ソフトウェアは、ビデオベースのビジネスにメリットをもたらします。企業がビジネスをより安全に管理および成長させるのに役立ちます。 SaaS サービスのソフトウェア ソリューションと組み合わせて使用できます。このソフトウェアは、認識、高度な言語推論、およびマルチモーダル ビデオ分析を組み合わせています。動画データの内容を理解することにつながります。コンテキスト広告構成の動画で使用できます。 Valossa を使用すると、没入感を実現できます ビデオオンデマンド (VOD)と オーバーザトップ (OTT) ユーザー エクスペリエンス。
Thetake.ai
Thetake.ai は動画を理解する人工知能ツールです。機械学習を使用して、ビデオ内の人や製品を自動的に識別します。このソフトウェアは、買い物可能なコンテンツをサポートするコンテンツ作成者に適しています。コンテンツを見ている人は、より効率的に目的の商品を見つけることができます。製品の発見とコンテンツのエンゲージメントを変革したい企業を支援します。それを使用することで、参加者のエクスペリエンスを向上させることもできます。
ビデオ認識の制限
多数のアプリケーションにもかかわらず、ML ベースのコンピューター ビジョン アプローチには制限がないわけではありません。このテクノロジーの主な課題の 1 つは、分析する必要があるデータの量です。 1 つのビデオには数千のフレームが含まれる場合があります。このデータの分析は、時間とリソースを大量に消費する可能性があります。さらに、ビデオ認識アルゴリズムは、低品質または不十分な照明の映像でオブジェクトまたは人物を正確に識別するのに苦労する可能性があります。
現在および将来の開発
ビデオ認識の分野は常に進化しており、精度と効率を向上させるために新しいテクノロジと手法が開発されています。主な重点分野の 1 つは、大量のデータをリアルタイムで正確に分析できる、より高度な機械学習アルゴリズムの開発です。また、複数の言語やコンテキストでオブジェクトやアクションを認識して分類するビデオ認識アルゴリズムの開発も推進されています。
雇用への影響
ビデオ認識技術は、多くの業界に革命を起こす可能性を秘めていますが、労働力を混乱させる可能性もあります。自動化と特定の業界での人工知能の使用は、機械が特定のタスクを完了するのにより熟達しているため、失業につながる可能性があります。しかし、映像認識技術の採用は、この技術の開発と維持に関連する分野で新しい雇用機会を生み出す可能性もあります。
上記の学習により、ML ベースのコンピューター ビジョン アプローチについて予備的な理解が得られたと確信しています。ビデオ認識は、マシンが大量の情報を理解するのに役立ちます。また、この情報を有意義で実用的なデータに変換して、私たちが利用できるようにします。
ビデオ認識に関する一般的な Q&A
-
ビデオ認識とは?
ビデオ認識は、人工知能とコンピューター ビジョンを使用してビデオ コンテンツを分析および理解するテクノロジーの一種です。
-
ビデオ認識はどのように機能しますか?
ビデオ認識では、アルゴリズムを使用してビデオ データを分析し、ビデオ内のオブジェクト、人物、アクションを識別して、関連情報を抽出します。
-
ビデオ認識のアプリケーションは何ですか?
ビデオ認識は、セキュリティと監視、ヘルスケア、輸送、エンターテイメント、広告など、さまざまな業界で応用されています。
-
ビデオ認識は画像認識とどう違うのですか?
ビデオ認識はビデオ シーケンスの複数のフレームを分析しますが、画像認識は単一の画像を分析します。ビデオ認識は一時的な情報も考慮し、物体や人を経時的に追跡できます。
-
ビデオ認識を使用して分析できるデータの種類は何ですか?
ビデオ認識は、人間の行動、車両の交通量、店舗での商品の配置、動物の行動など、幅広いデータを分析できます。
-
ビデオ認識をリアルタイム分析に使用できますか?
はい、ビデオ認識をリアルタイム分析に使用できるため、イベントや状況に即座に対応できます。
-
ビデオ認識技術の実装コストはいくらですか?
ビデオ認識技術を実装するコストは、タスクの複雑さと分析するデータの量によって異なります。
-
ビデオ認識をマーケティングや広告にどのように使用できますか?
ビデオ認識をマーケティングや広告で使用して、消費者の行動を分析し、広告キャンペーンの効果を追跡し、ユーザーの好みに基づいてコンテンツをパーソナライズできます。

 ガイド")




{kind=link}